Setting up Spark and PyCharm the hard way...
I only say the hardway because it ended up being more tedious than I remember compared to using Spark with Scala. I still prefer Scala to the Python implementation of Spark but in some cases Scala might be a bit heavy handed so thats where PySpark can come in handy. This goes over setting up the basic dev environment and getting it setup in your PyCharm projects. This tutorial assumes you are running Mac OSX and have the base dependencies in place to run spark such as java 7+, python 2.7+ or python 3.1+ etc. These steps will be very similar to how you can setup spark on a linux environment as well.
Setting Up the Environment
First and formost you need to grab Spark from the Apache site here. The latest version 1.6.1 should be compatible with current instances of EMR if you are on AWS or whichever version you need for your own personal Hadoop cluster. There is also the option for a hadoop free build of spark but I have not looked into that yet. Once that is downloaded extract the tar into your favorite library location. For myself I created a directory under /opt.
mkdir -p /opt/spark-1.6.1
Then extract the content of the spark archive into there. Next you will want to set SPARK_HOME on your path. If you do not already have a .bash_profile setup you will want to create one now. I did this below with the following command. You might need to be sudo for this to work.
Create the bash_profile
sudo touch ~/.bash_profile
Add SPARK_HOME to the location of your spark install inside .bash_profile
export SPARK_HOME=/opt/spark-1.6.1
export PATH=$SPARK_HOME/bin:$PATH
Once this is done you should just need to restart the terminal and start up spark-shell in the command line.
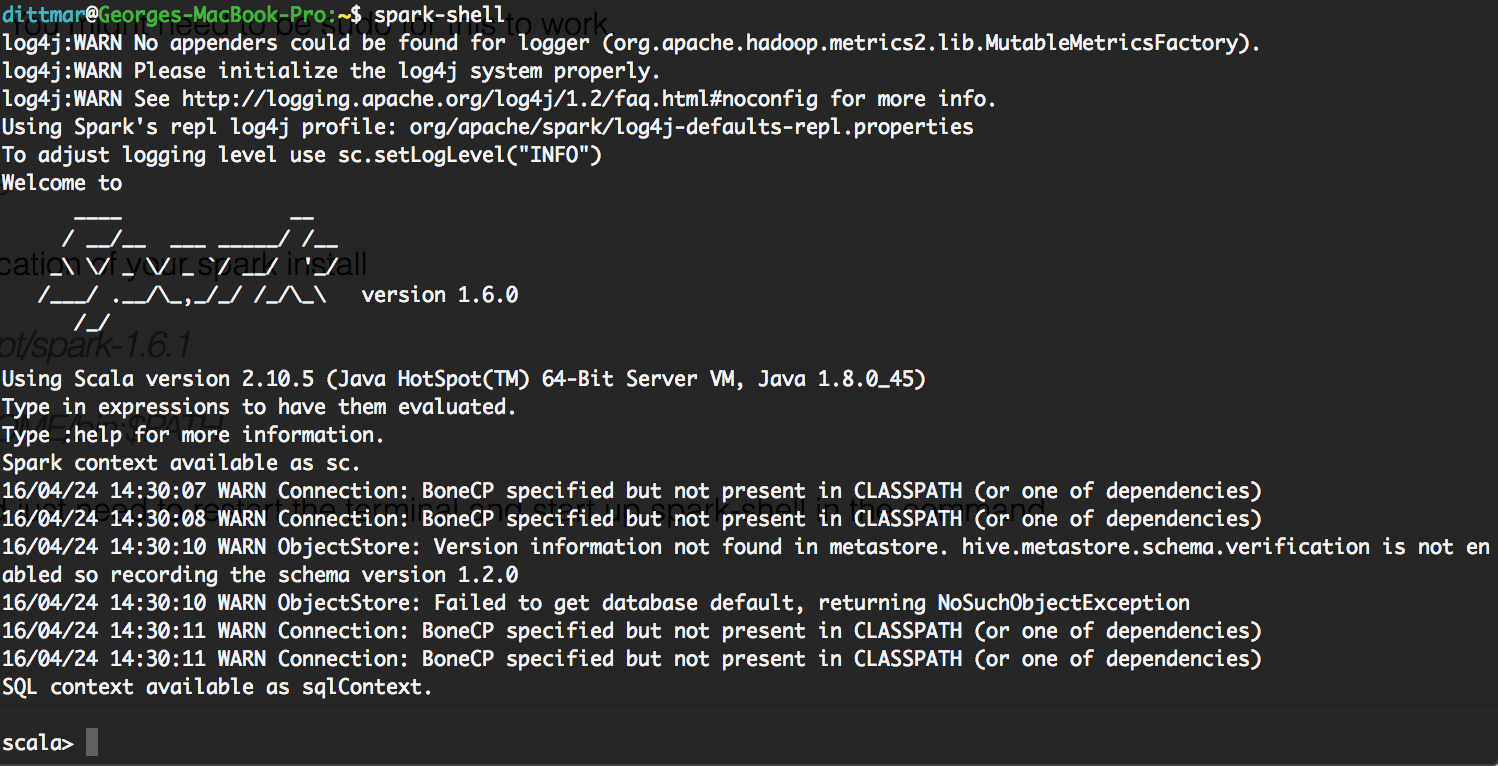
If the shell comes up then you have successfully installed spark on your Mac! Next lets set it up to work with pycharm IDE for easy pyspark development.
Setting up PyCharm
Now lets try to setup pyspark in pycharm so that we can code and run jobs inside the IDE. First grab the git repo I have here so that we can verify the setup is correct and run a pyspark script. Once that is cloned down open pycharm and load up the project. First we need to setup the interpreter to correctly load the spark dependencies we need. Go to the Project Interpreter.
File -> Default Settings -> Project Interpreter
You should see this screen below.

Then click on the gear at the top right and select more to get you to this screen…
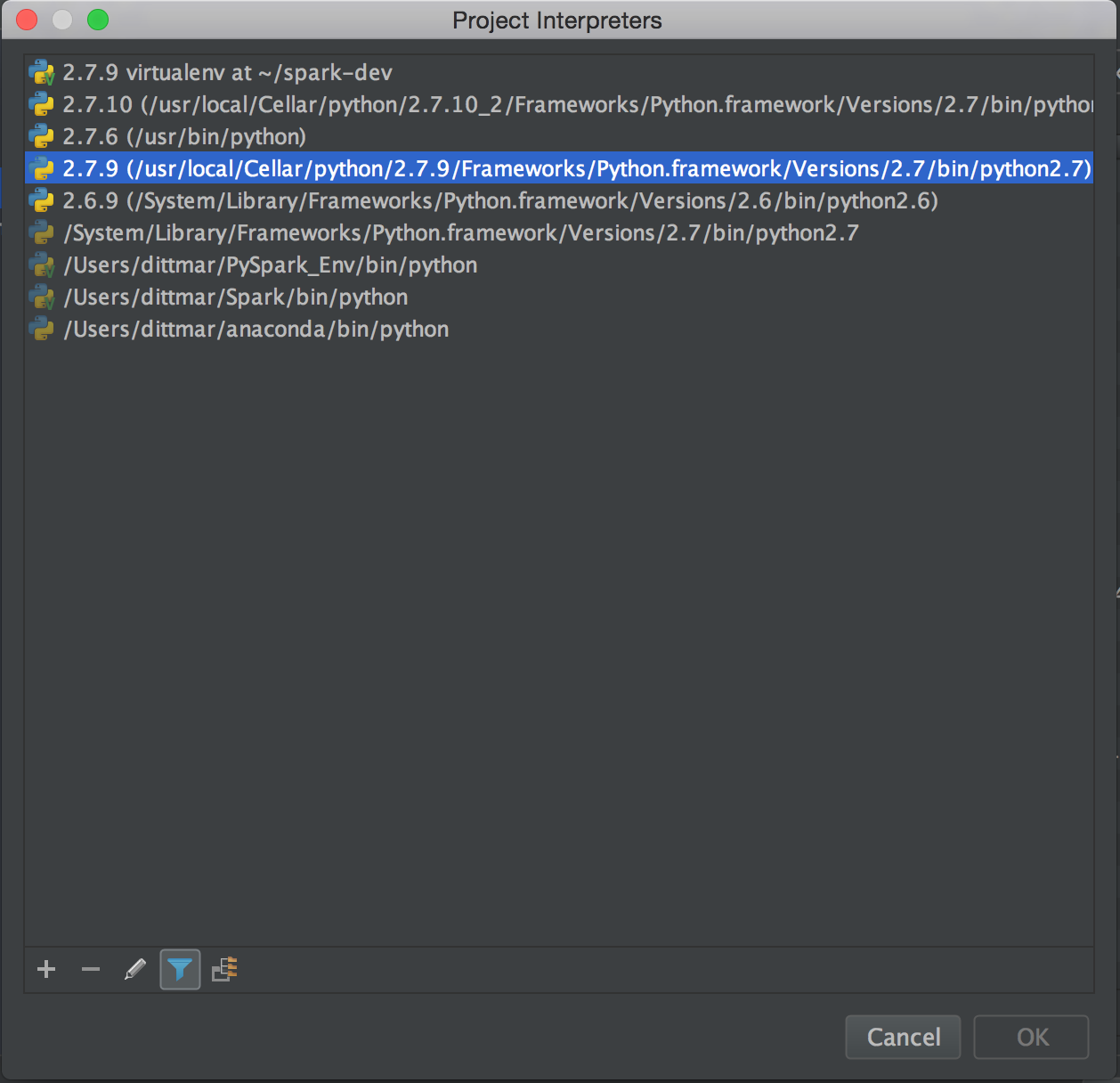
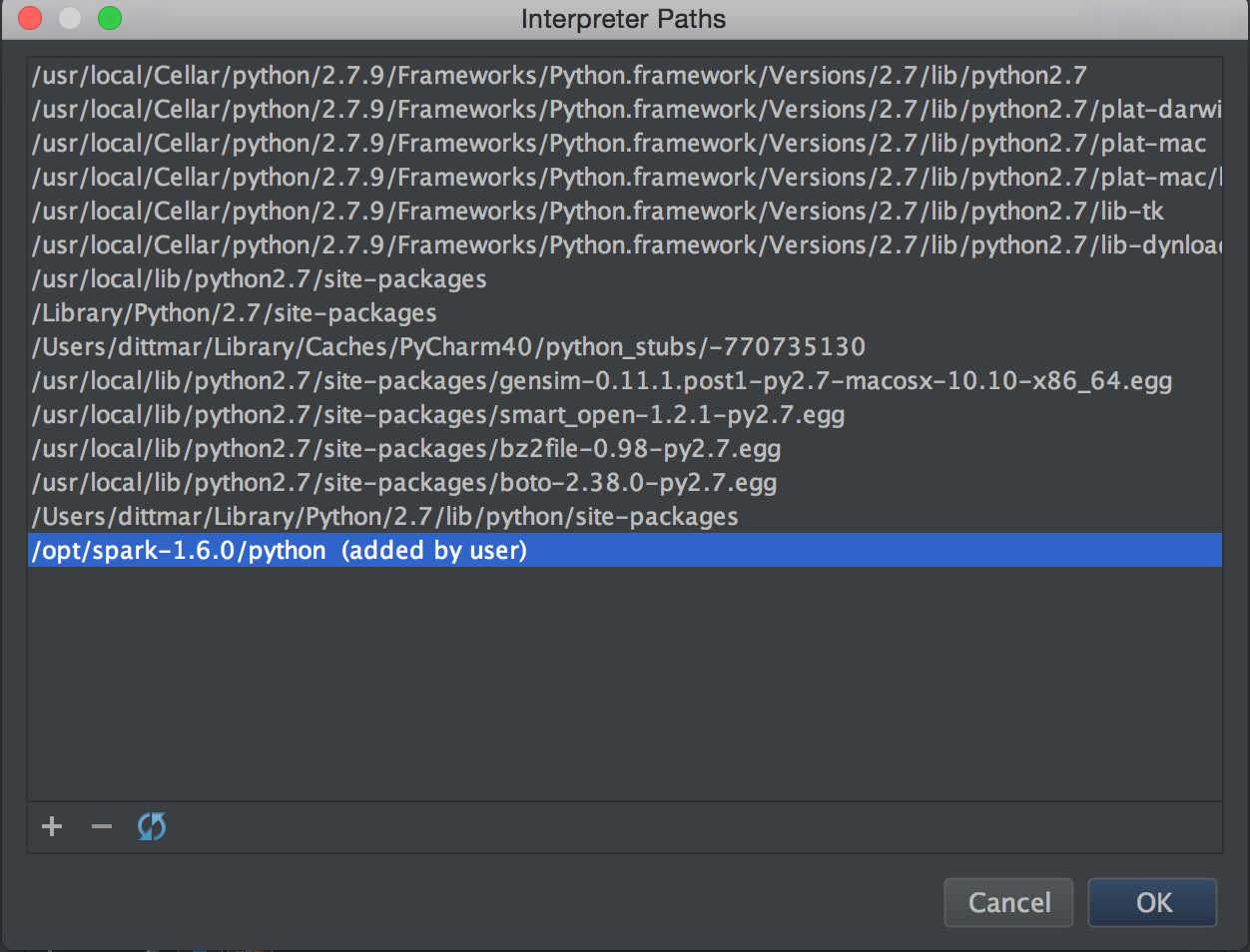
Then click the file structure icon at the bottom left and click the plus symbol on the next screen to set the path to the local spark install at /opt/spark-1.6.1/python. We want to go to the python directory since we will only be working with python.

Once that is done you should now see it in the list of interpreter paths python will load up and have access to while you develop.
Now lets see if pycharm works correctly with one of the example scripts. Lets take a look at the TextCounts.py example script. This script just reads in the sample.txt file which is a chapter from a book found on the gutenberg project that will use spark locally to count up the number of times a word is in a document then calculate the term frequency for every word. Right click on the source file and hit run. You should see output like below in the IDE’s console. If it runs correctly you should now see which terms are the most frequent from that sample document and can now tell all your friends this great stat that was solved using Spark!
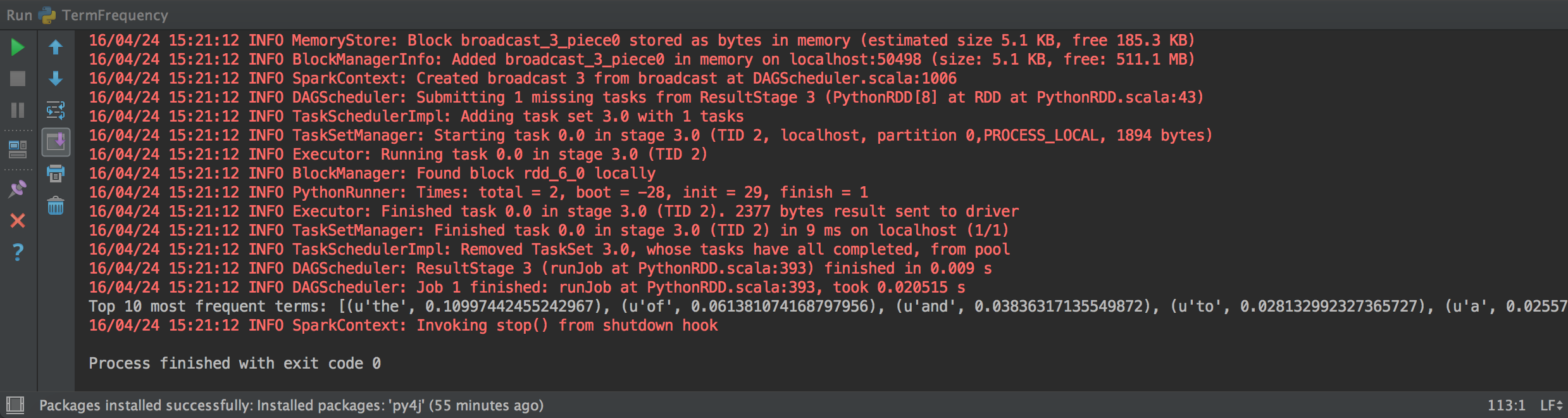
If you do not see the above output and get some sort of error below like py4j not installed or found then you will need to add that to pycharm manually as well, though it comes packaged with pyspark so should be brought in when loading the interpreter.

To resolve this you will need to pull down py4j and luckily pycharm has a package manager to help with that so you can get running quickly. Go back to the Default Settings screen like earlier and down at the bottom left hit the plus button. That will bring up the package manager that you can then search for py4j. Select the py4j package, not the asphalt-py4j package, and hit install package.
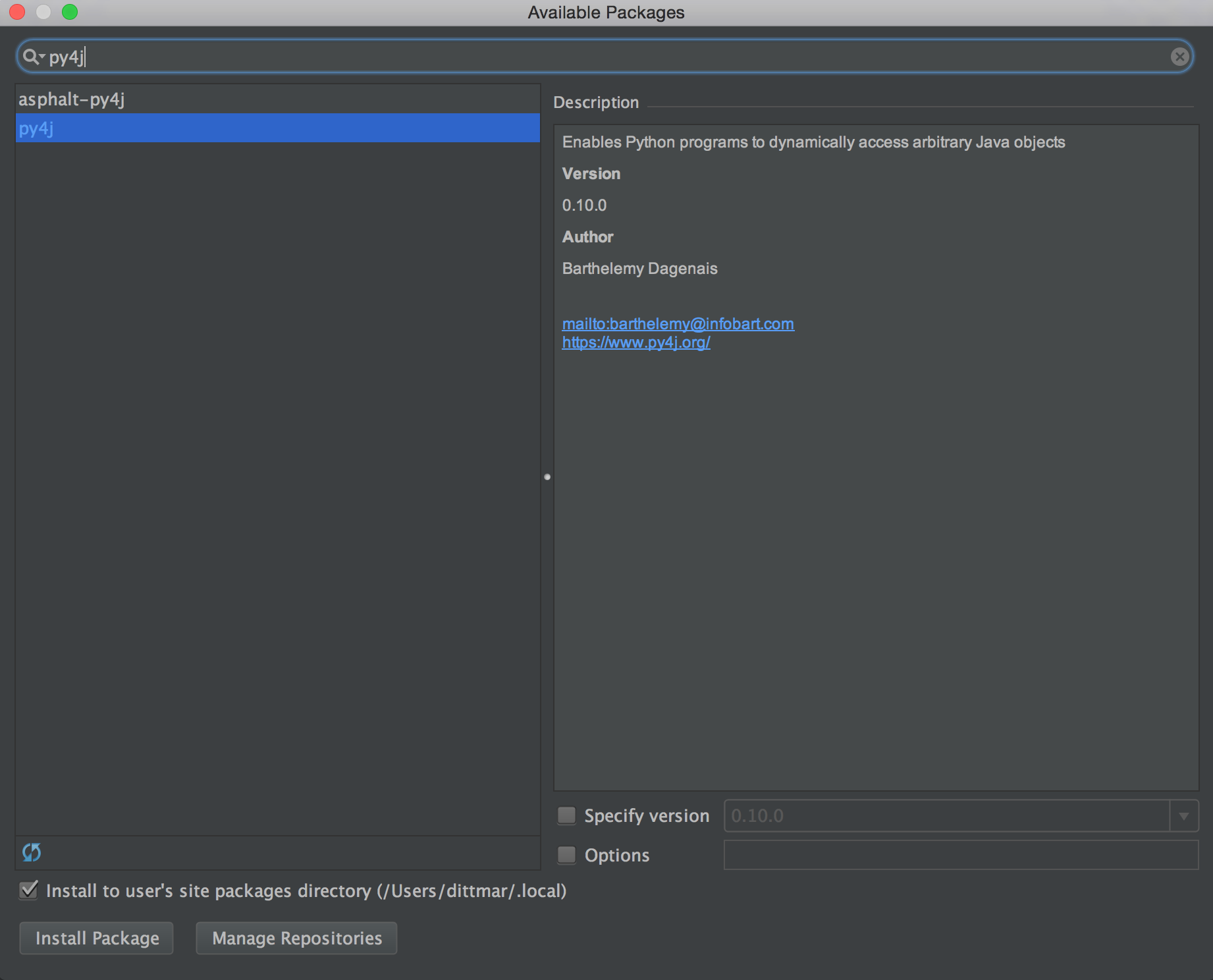
Once that is installed rerun the script and it should now work! Let me know if this was helpful or not or if there are other topics I could cover around spark. Now also whenever you create a new project in pycharm you should have access to all that you already setup previously with the python interpreter so you should not need to repeat these steps unless you download a new version of spark.